数据库
Count(*)、Count(1)、Count(0)、Count(id)、Count(name)之间的区别?
Count都会进行一次全表便利,Count(*)、Count(1)、Count(0)不会从底层获取数据,直接进行count++。但是id和name会从底层获取数据进行判断是否为null才进行count++。此外MySQL会借助占用页最小的索引进行遍历。
系统设计
怎么避免单点故障(SPOF、Single Point of Failure)?
- Redundancy(冗余): Primary vs Standby,比如流量入口,load banlaner进行主备
- Load Balancing(负载均衡)
- Data Replication(数据复制): 数据库、缓存的主从
- Geographic Distributio(异地多活):异地多集群的数据复制(同步或异步)
- Graceful Handling of Failures
- Monitoring and Alerting
技术选型
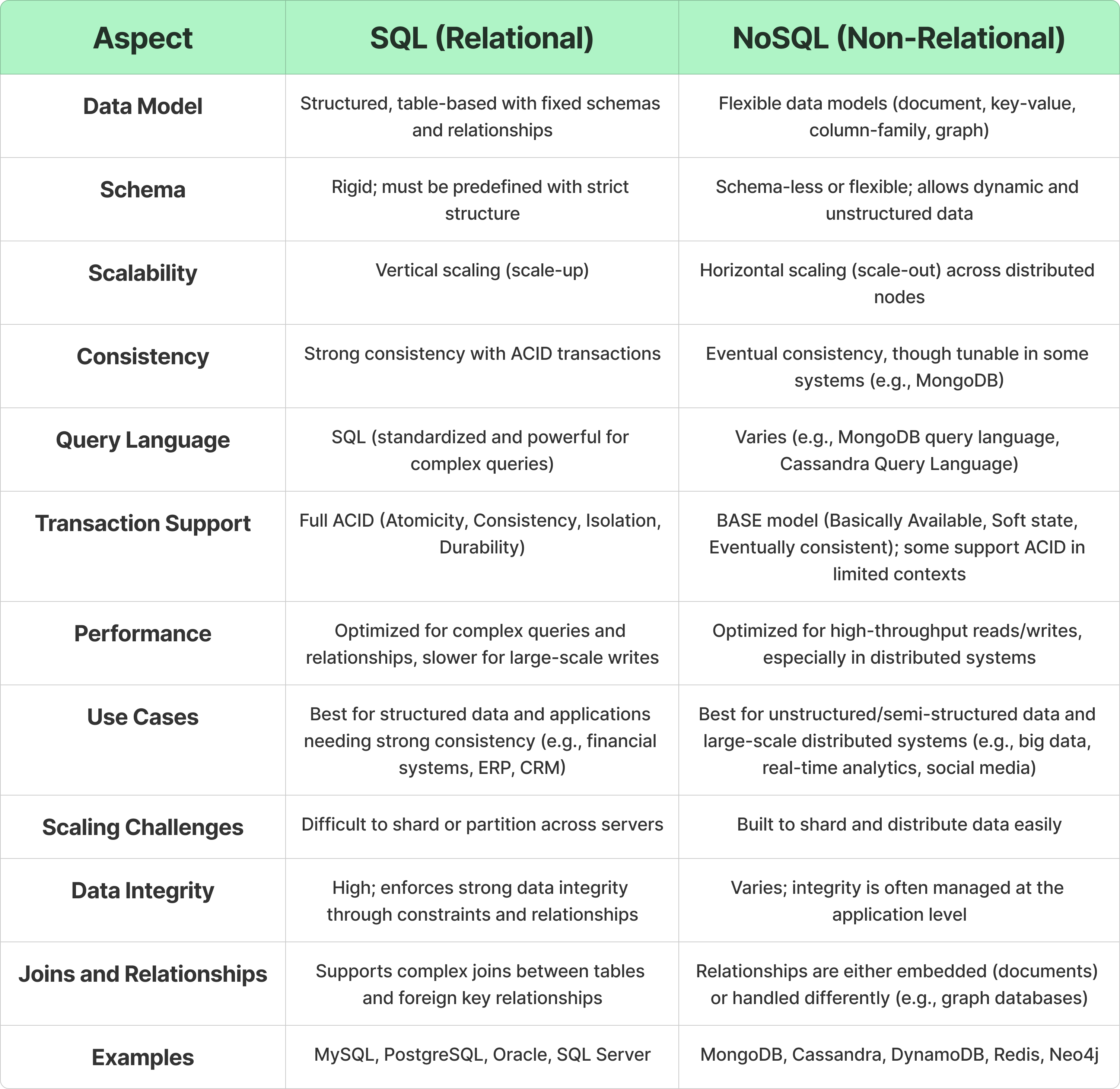
SQL vs NoSQL
- 数据模型: schema vs schema-less(Key-Value Model, Document Model, Column-Family Model, Graph Model )
- 扩展性: 垂直扩展 vs 水平扩展
- 查询语言:SQL vs 无固定标准
- 事务:ACID vs BASE
- 性能:对Schema明确,查询模式固定的方式,SQL查询效率高
具体系统设计Blog
- Design Spotify - System Design Interview
- Design a Scalable Notification Service - System Design Interview
参考资料
- 麻烦不要再问我count(*)、count(1)、count(id)、count(name)之间的区别了
- System Design: How to Avoid Single Point of Failures?
- SQL vs NoSQL - 7 Key Differences You Must Know
网络协议
DNS 完整查询过程?
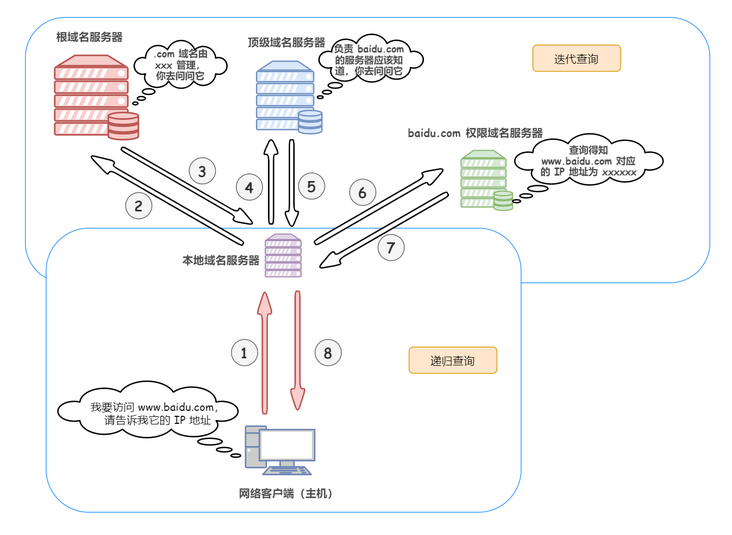
DNS 查询请求过程和域名缓存结合起来,完整查询过程👇:
- 首先搜索 浏览器的 DNS 缓存 ,缓存中维护一张域名与 IP 地址的对应表
- 如果没有命中😢,则继续搜索 操作系统的 DNS 缓存
- 如果依然没有命中🤦♀️,则操作系统将域名发送至 本地域名服务器 ,本地域名服务器查询自己的 DNS 缓存,查找成功则返回结果(注意:主机和本地域名服务器之间的查询方式是 递归查询 )
- 若本地域名服务器的 DNS 缓存没有命中🤦,则本地域名服务器向上级域名服务器进行查询,通过以下方式进行 迭代查询 (注意:本地域名服务器和其他域名服务器之间的查询方式是迭代查询,防止根域名服务器压力过大):
- 首先本地域名服务器向根域名服务器发起请求,根域名服务器是最高层次的,它并不会直接指明这个域名对应的 IP 地址,而是返回顶级域名服务器的地址,也就是说给本地域名服务器指明一条道路,让他去这里寻找答案
- 本地域名服务器拿到这个顶级域名服务器的地址后,就向其发起请求,获取权限域名服务器的地址
- 本地域名服务器根据权限域名服务器的地址向其发起请求,最终得到该域名对应的 IP 地址
- 本地域名服务器 将得到的 IP 地址返回给操作系统,同时自己将 IP 地址 缓存 起来📝
- 操作系统 将 IP 地址返回给浏览器,同时自己也将 IP 地址 缓存 起来📝
- 至此, 浏览器 就得到了域名对应的 IP 地址,并将 IP 地址 缓存 起来📝
TCP建立连接(3次握手)流程
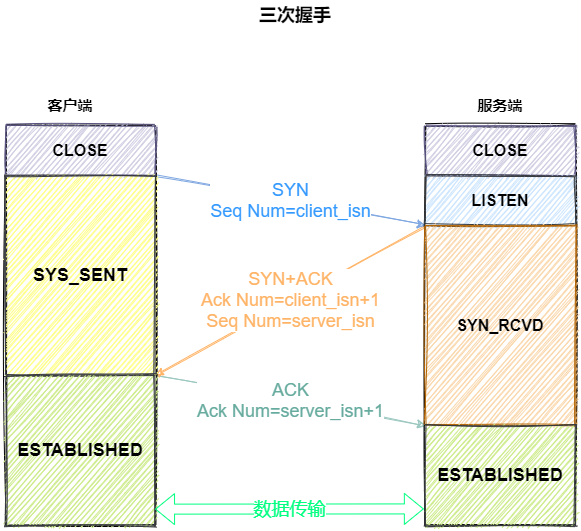
为什么需要3次?
- 为了防止服务器端开启一些无用的连接增加服务器开销
- 防止已失效的连接请求报文段突然又传送到了服务端,因而产生错误。
TCP断开连接(4次挥手)流程
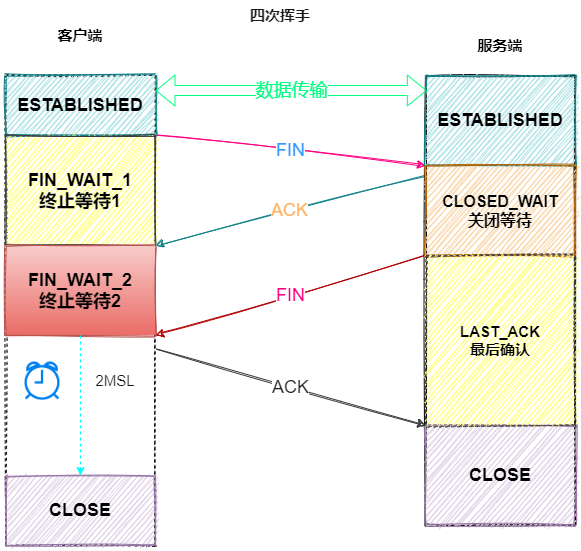
为什么客户端在TIME-WAIT阶段要等2MSL?
为的是确认服务器端是否收到客户端发出的 ACK 确认报文