Chapter 1: The Machine Learning Landscape
机器学习分类:
是否监督
- 监督学习(Supervised learning)
- 非监督学习(Unsupervised learning)
- 半监督学习(Semi-supervised learning)
- 自监督学习(Self-supervised learning)
- 强化学习(Reinforcement learning)
批量vs在线学习
- Batch learning
- Online learning
Instance-Based Versus Model-Based Learning
- Instance-based learning
- Model-based learning and a typical machine learning workflow
机器学习的主要挑战
- 训练数据量不足(Insufficient Quantity of Training Data)
- 非代表性训练数据(Nonrepresentative Training Data)
- 劣质数据(Poor-Quality Data)
- 不相关特征(Irrelevant Features)
- 过拟合(Overfitting the Training Data)
- 欠拟合(Underfitting the Training Data)
Chapter 2: End-to-End Machine Learning Project
通过一个预测房价的实例介绍机器学习实践流程。
前提是明确需求的情况下,现在手里有一份数据。怎么开始进行机器学习。
- 首先了解数据,整体熟悉数据结构。
- panda查看数据统计
- matplotlib绘制图标
- 创建测试集
- 分层抽样
- 测试集不要在训练阶段使用
- 抽样要随机
- 结果要保持一致,不要多次创建测试集后,让模型学习了所有数据
- 看看数据分布
- 看看相关性(Correlations)
- 尝试组合特征
- 数据预处理
- 缺失值补齐
- 处理分类数据
- 特征缩放
- 选择和训练模型
- 尝试不同的模型
- 交叉验证不同模型的效果
- 微调模型
- Grid Search
- Randomized Search
- 分析模型和错误
- 在测试集上评估模型
- 上线模型
Chapter 3: Classification
通过一个识别手写数字的实例介绍分类。
识别手写数字和预测房价不同的地方在于Performance Measures。预测房价使用是通哟RMSE(root mean squred error)。识别手写数字这里使用这种方式就会有误导。
- 混淆矩阵(Confusion Matrices)
- 准确率和召回率(Precision and Recall)
- ROC缺陷(The ROC Curve)
分类又可以分为多种
- Multiclass Classification
- Multilabel Classification
- Multioutput Classification
Chapter 4: Training Models
梯度下降
梯度下降是一种通用的优化算法,能够找到各种问题的最优解。梯度下降的一般思想是迭代地调整参数,以最小化成本函数。
学习率是梯度下降中的重要参数
- 太大,可能导致在最优解左右横跳,甚至远离最优解
- 太小,训练时间太长,过早停止无法找到最优解
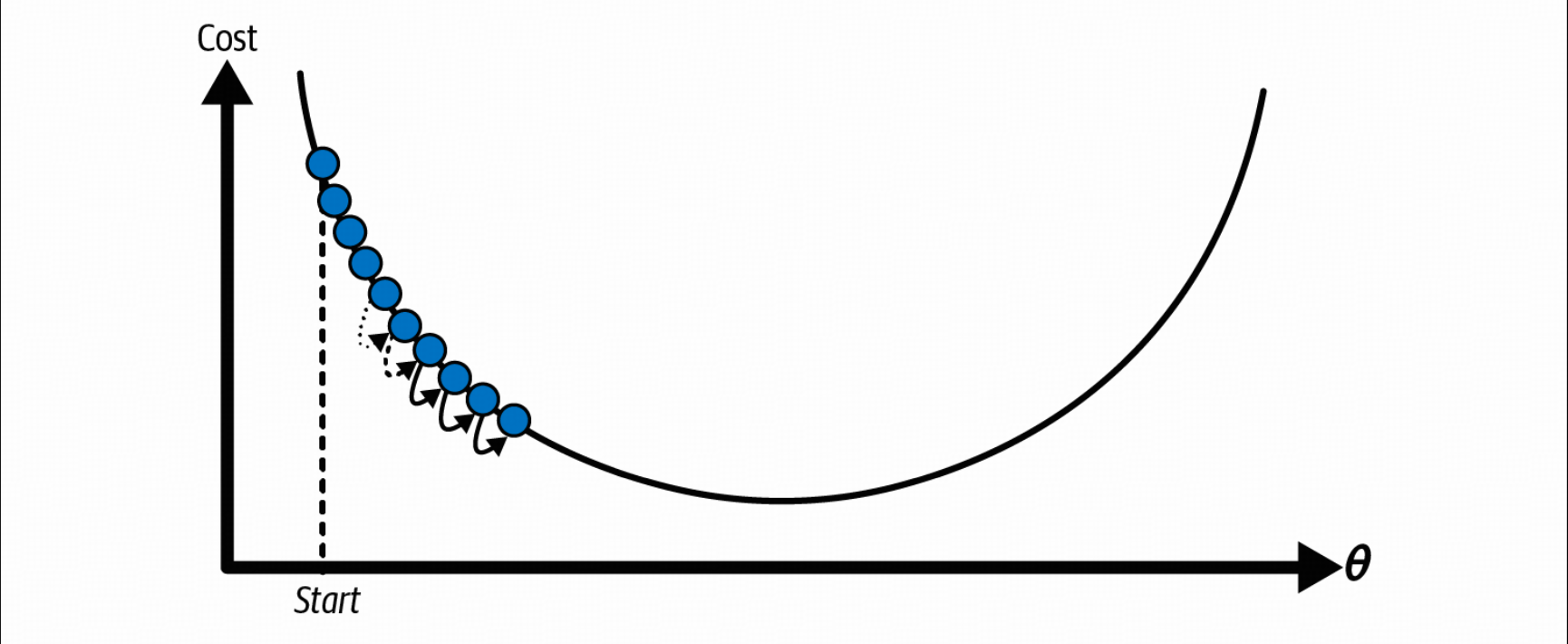
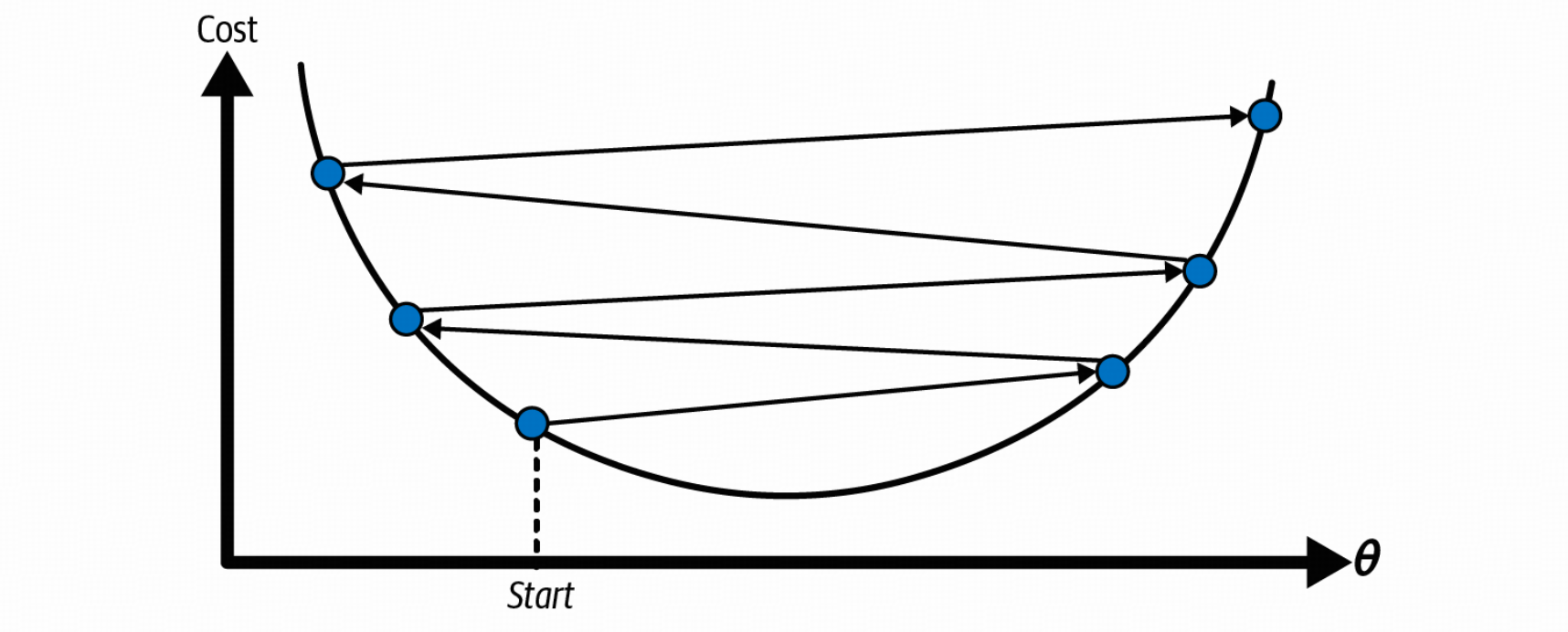
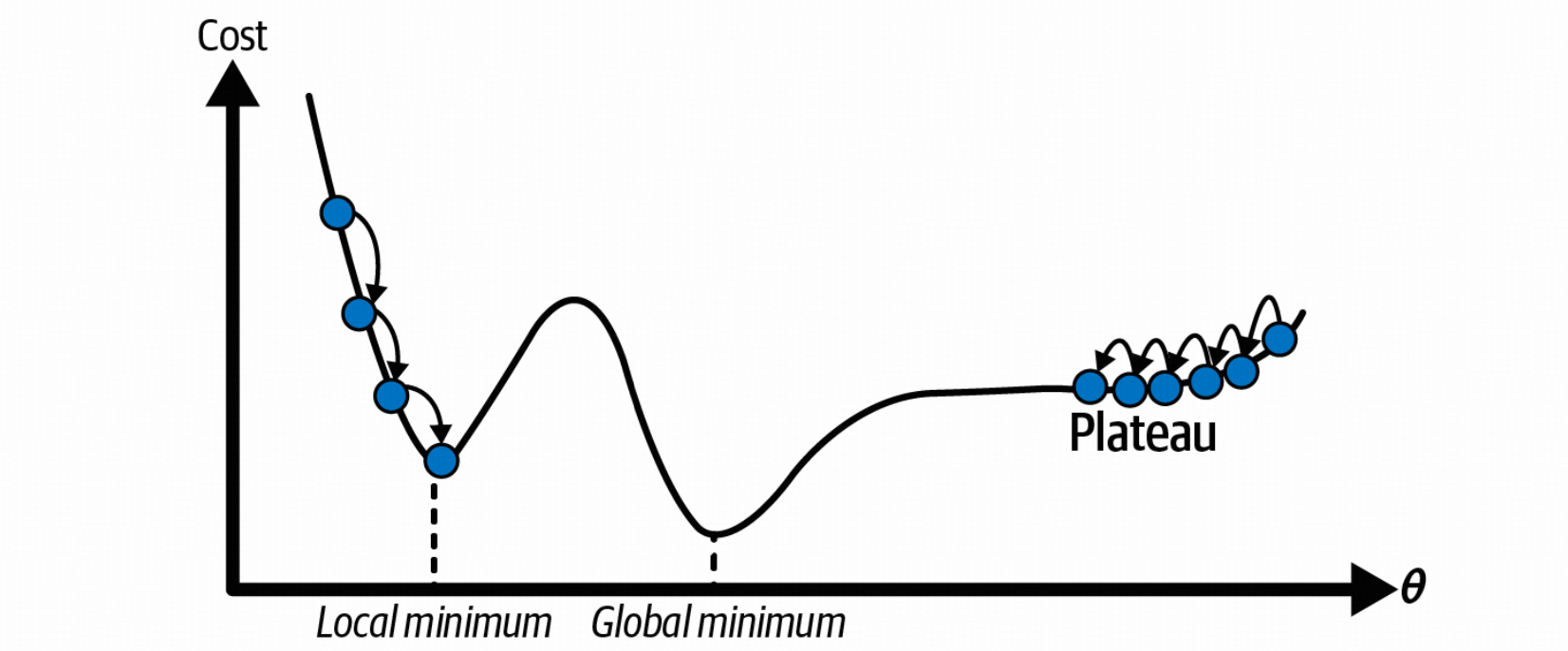
梯度下降本身有一些缺陷
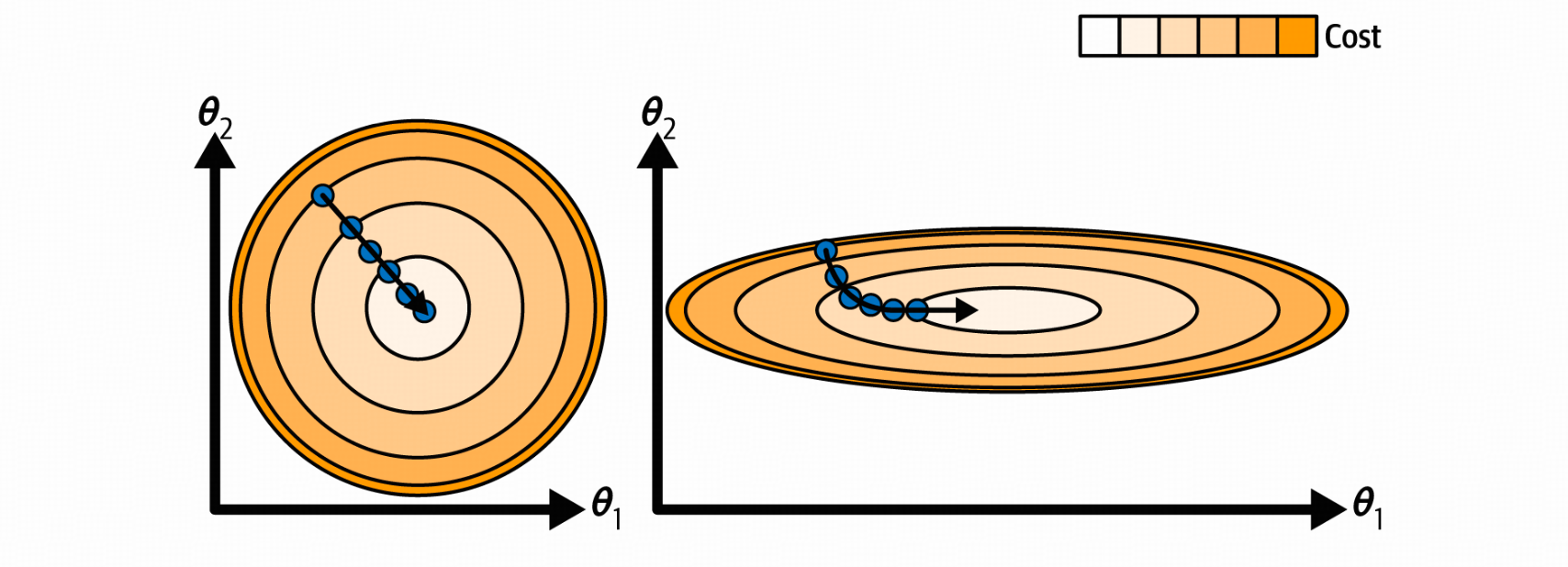
特征拥有不同的scaling的情况下学习效率低
随机梯度下降
批量梯度下降的主要问题在于,它在每一步使用整个训练集来计算梯度,这使得在训练集很大时非常缓慢。
随机梯度下降 在每一步选择训练集中的一个随机实例,并仅基于该单个实例计算梯度。
更快的计算的同时,带来了不规则性
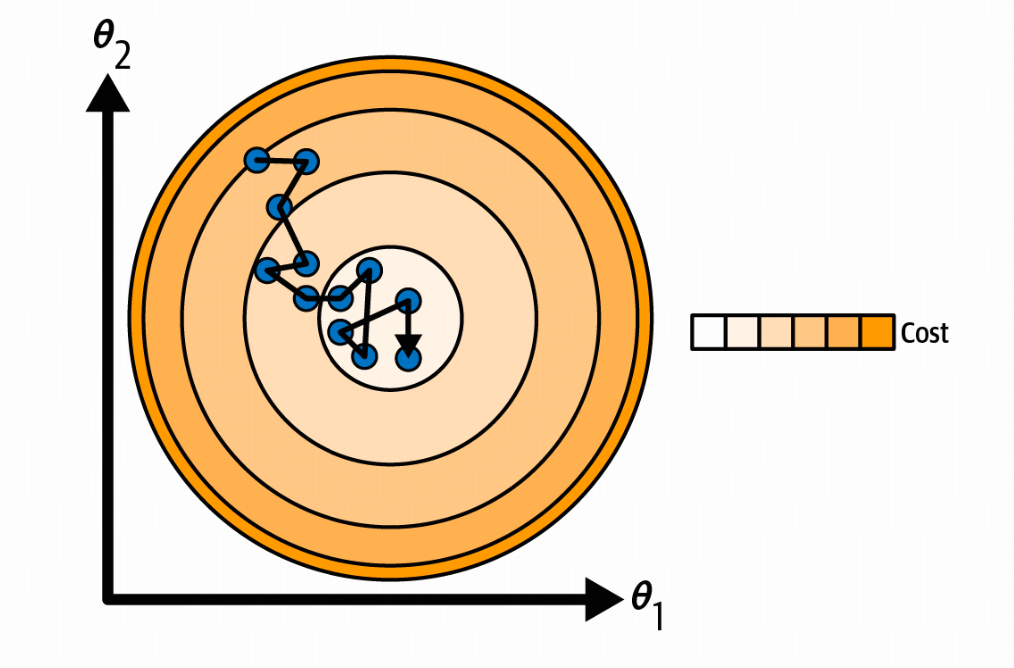
因此,随机性有助于摆脱局部最优解,但也不好,因为这意味着算法永远无法稳定在最小值处。
解决方法:
- 逐渐降低学习率
小批量梯度下降
在每一步中,小批量梯度下降不是基于完整训练集(批量梯度下降)或仅基于一个实例(随机梯度下降)计算梯度,而是在称为小批量的小随机实例集上计算梯度。小批量梯度下降相对于随机梯度下降的主要优势在于,您可以通过硬件优化矩阵运算获得性能提升,尤其是在使用 GPU 时。
多项式回归
可以使用线性模型来拟合非线性数据。将每个特征的幂作为新的特征进行拟合。
但是高阶的参数容易导致模型过拟合。因此需要正则化线性模型
- Ridge Regression
- Lasso Regression
- Elastic Net Regression
- Early Stopping